Temps de lecture estimé : 14 minutes
Points clés à retenir
- Kimi K2.6 est numéro 1 des modèles open weights en 2026 (score 54 sur AI Intelligence Index) et domine sur le coding (SWE-Bench Pro 58,6 %), l’agentic et le multimodal (support image).
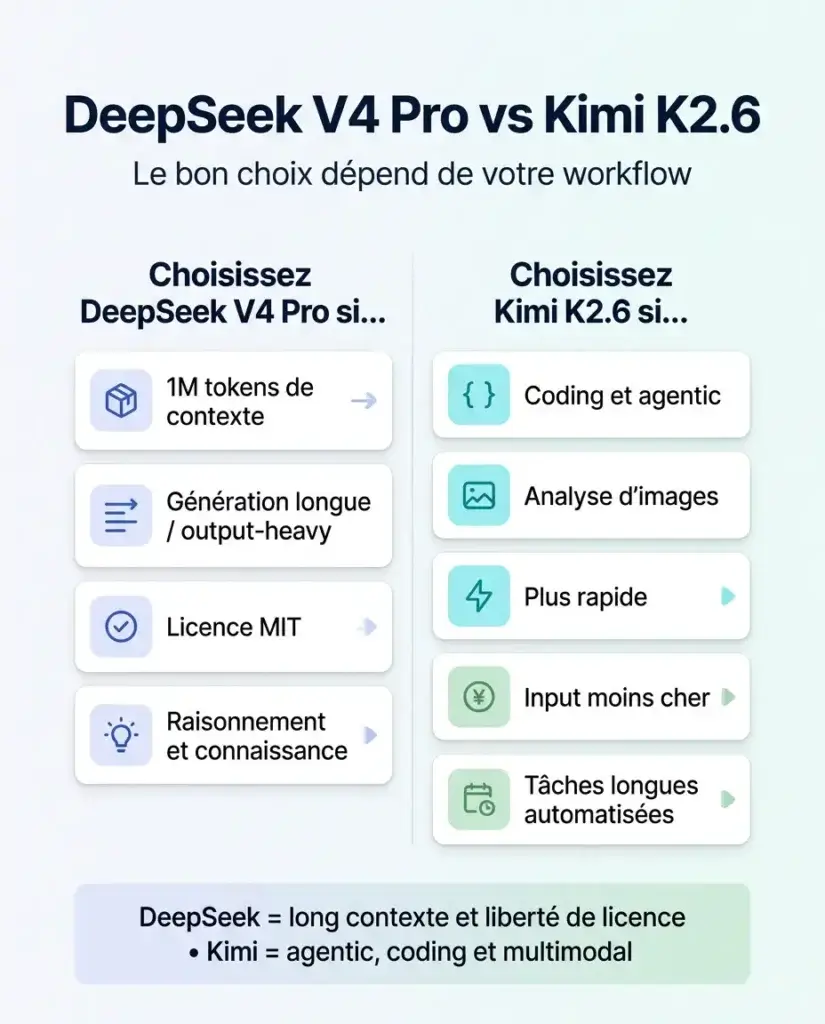
- DeepSeek V4 Pro s’impose sur le context window (1M tokens vs 256k), la licence MIT sans restriction commerciale, et le coût output (3,48 $ vs 4,00 $ par million de tokens).
- Le choix dépend exclusivement du workflow : agentic / coding / images → Kimi K2.6 ; long context / génération intensive / licence libre → DeepSeek V4 Pro.
- Les deux modèles sont sortis en avril 2026 avec une architecture Mixture of Experts (MoE) et challengent frontalement GPT-5 et Claude sur le segment open source.
DeepSeek V4 Pro vs Kimi K2.6 : lequel choisir en 2026 ?
En avril 2026, la comparaison DeepSeek V4 Pro vs Kimi K2.6 est devenue LA question que tout le monde se pose dans le monde de l’IA open source. Deux géants chinois, sortis à quatre jours d’intervalle, qui s’invitent dans la cour des propriétaires — GPT-5, Claude, et consorts — sans complexe. Et franchement, ils n’ont pas tort de le faire.
Soyons honnêtes : les deux modèles sont impressionnants sur le papier. Mais « impressionnant sur le papier », ça ne vous aide pas à décider lequel intégrer à votre workflow, votre stack technique, ou vos outils d’automatisation.
C’est exactement pour ça que j’ai passé du temps à décortiquer les benchmarks, comparer les prix et éplucher les tests terrain — pour vous éviter de le faire vous-même.
On va voir ensemble l’intelligence, le pricing, le context window, les capacités de coding et d’agentic, le support image, et je vous donne un verdict clair. Spoiler alert : la réponse n’est pas la même selon ce que vous faites concrètement. Mais on y arrive.
DeepSeek V4 Pro et Kimi K2.6 : deux titans open source en 2026
Avant de rentrer dans les chiffres, posons le décor. Ces deux modèles, c’est l’architecture Mixture of Experts (MoE) — en clair, un modèle géant qui n’active qu’une petite partie de ses neurones à chaque inférence. Résultat : moins de calcul, plus de vitesse, sans sacrifier l’intelligence.
| Critère | DeepSeek V4 Pro | Kimi K2.6 |
|---|---|---|
| Créateur | DeepSeek (Chine) | MoonshotAI (Chine) |
| Date de sortie | 24 avril 2026 | 20 avril 2026 |
| Paramètres totaux | ~1 600 milliards | ~1 000 milliards |
| Paramètres actifs | ~49 milliards | ~32 milliards |
| Licence | MIT (ouverte commercialement) | « Other » (à vérifier avant usage commercial) |
| Open source | Oui — weights sur HuggingFace | Oui — weights sur HuggingFace |
| Support image (input) | Non — texte uniquement | Oui — texte + images |
| Context window | 1 000 000 tokens | 256 000 tokens |
En clair : DeepSeek V4 Pro est plus massif en paramètres actifs, avec une fenêtre de contexte 4x plus large et une licence MIT qui laisse toutes les portes ouvertes. Kimi K2.6 est plus léger à l’inférence, supporte les images, et s’est taillé une réputation sérieuse en agentic et coding.
Conseil Romain : Soyons honnêtes — les deux modèles viennent de Chine et bousculent sérieusement le leadership américain. En 2026, l’open source IA a rattrapé les propriétaires. C’est une excellente nouvelle pour les PME qui ne veulent pas payer des fortunes en abonnements API.
Intelligence et benchmarks : qui est le plus capable ?
C’est la question que tout le monde pose en premier, et c’est normal. Alors, chiffres à l’appui : sur l’Artificial Analysis Intelligence Index, Kimi K2.6 obtient un score de 54, ce qui le place numéro 1 des modèles open weights en mai 2026. DeepSeek V4 Pro (en mode raisonnement maximum) arrive à 52. L’écart est réel, même s’il reste serré.
| Benchmark | Kimi K2.6 | DeepSeek V4 Pro | Avantage |
|---|---|---|---|
| AI Intelligence Index | 54 / 100 | 52 / 100 | Kimi K2.6 |
| SWE-Bench Pro (coding) | 58,6 % | Non mesuré en comparatif direct | Kimi K2.6 |
| Terminal-Bench 2.0 | 66,7 % (+16 pts vs K2.5) | Estimé inférieur | Kimi K2.6 |
| LiveCodeBench v6 | 89,6 % | Estimé comparable | Kimi K2.6 |
| HLE avec outils | 54,0 % | Estimé comparable | Kimi K2.6 |
| GPQA Diamond (connaissance) | Estimé comparable | Fort | DeepSeek V4 Pro |
« Kimi K2.6 dépasse GPT-5.4 sur SWE-Bench Pro (58,6 % vs 57,7 %) — ce qui en fait le meilleur modèle open source pour le coding en 2026, selon Artificial Analysis. »
Spoiler alert : sur les benchmarks agentic et coding, Kimi K2.6 prend clairement le dessus. DeepSeek V4 Pro tient ses positions sur la connaissance pure et le raisonnement structuré. On se dit tout ? La différence n’est pas énorme — mais dans les tâches de développement, c’est celle qui compte.
Contexte window : 1 million vs 256 000 tokens — ce que ça change vraiment
C’est le différenciant le plus spectaculaire entre les deux modèles — et paradoxalement, celui que 95 % des utilisateurs ne verront jamais dans leur usage quotidien. Mais pour ceux qui en ont besoin, c’est un game-changer.
DeepSeek V4 Pro propose un context window d’1 million de tokens, soit l’équivalent d’environ 1 500 pages A4. Kimi K2.6 plafonne à 256 000 tokens, soit environ 384 pages A4. C’est encore énorme — mais 4x moins.
| Modèle | Context Window | Équivalent pages A4 | Usage recommandé |
|---|---|---|---|
| DeepSeek V4 Pro | 1 000 000 tokens | ~1 500 pages | RAG intensif, analyse de très longs corpus, documentation technique exhaustive |
| Kimi K2.6 | 256 000 tokens | ~384 pages | Conversations longues, code review, résumés de rapports, chat historique roulant |
Dans les tests terrain, DeepSeek V4 Pro reste précis jusqu’à 600 000 tokens. Au-delà, la cohérence se maintient mais la précision diminue légèrement. Kimi K2.6, lui, commence à « résumer » au-delà de 200 000 tokens dans les requêtes très complexes — ce qui est un comportement normal mais à garder en tête pour les applications critiques.
En clair : Si vous traitez des documents de 400+ pages en continu ou construisez un système RAG sur une base documentaire massive, DeepSeek V4 Pro est votre ami. Pour tout le reste — et c’est 95 % des cas en PME — Kimi K2.6 suffit amplement. Ne vous laissez pas impressionner par les grands nombres.
Pricing : lequel coûte vraiment moins cher ?
Bonne nouvelle et mauvaise nouvelle. Bonne nouvelle : les deux sont open source, donc théoriquement gratuits si vous les hébergez vous-même. Mauvaise nouvelle : héberger 1 600 milliards de paramètres demande un datacenter, pas un MacBook Pro.
En usage API (la réalité pour 99 % des entreprises), le pricing mérite une analyse fine. Parce que « moins cher en input » ne veut pas dire « moins cher à l’usage ».
| Modèle | Input (/ 1M tokens) | Output (/ 1M tokens) | Meilleur pour |
|---|---|---|---|
| DeepSeek V4 Pro | 1,74 $ | 3,48 $ | Usage output-heavy (génération longue, rédaction, code) |
| Kimi K2.6 | 0,95 $ | 4,00 $ | Usage input-heavy (analyse de docs, RAG, Q&A sur données) |
La clé, c’est le ratio input/output de votre usage réel. Pour un workflow d’analyse documentaire où vous envoyez de gros blocs de texte et attendez une réponse courte, Kimi K2.6 est moins cher. Pour un workflow de génération de contenu ou de code où l’output est long, DeepSeek V4 Pro gagne nettement (3,48 $ vs 4,00 $ à l’output).
En appliquant un ratio réaliste de 3:1 input/output (typique pour du coding ou de la rédaction), DeepSeek V4 Pro ressort globalement plus économique sur les usages intensifs en génération. Autant dire que le « moins cher » dépend entièrement de ce que vous faites.
Attention : Ces prix sont ceux d’OpenRouter en mai 2026. Les tarifs directs via api.deepseek.com ou platform.moonshot.cn peuvent différer. Comparez toujours avant de signer un contrat d’usage intensif.
Vitesse et latence : qui répond le plus vite ?
En clair : Kimi K2.6 est plus rapide. Et ce n’est pas une surprise — avec seulement 32 milliards de paramètres actifs contre 49 milliards pour DeepSeek V4 Pro, la mécanique MoE joue en sa faveur.
Dans les tests agentic documentés par kilo.ai, Kimi K2.6 affiche un throughput 185 % supérieur à ses versions précédentes — et surpasse DeepSeek V4 Pro en débit de tokens par seconde dans les workflows de longue durée. Les données officielles de latence TTFT (Time To First Token) ne sont pas publiées officiellement par les deux créateurs à date — ce qui est, soyons honnêtes, un manque dans la transparence du marché IA en général.
| Métrique | DeepSeek V4 Pro | Kimi K2.6 | Avantage |
|---|---|---|---|
| Paramètres actifs (MoE) | ~49 milliards | ~32 milliards | Kimi K2.6 (moins de calcul) |
| Throughput agentic (test terrain) | Référence | +185 % vs versions antérieures | Kimi K2.6 |
| Latence TTFT officielle | Non publiée | Non publiée | — Données manquantes — |
| Usage recommandé vitesse | Traitement batch, analyse profonde | Agents en temps réel, interactions rapides | Selon usage |
Pour les agents IA en temps réel — chatbots, pipelines d’automatisation avec réponse immédiate — la légèreté de Kimi K2.6 est un avantage concret. Pour des traitements batch nocturnes où la vitesse compte moins, la différence est négligeable.
Coding et agentic : le vrai terrain de jeu de ces deux modèles
C’est là que ça devient vraiment intéressant. Ces deux modèles ne sont pas des assistants de chat — ce sont des moteurs pensés pour l’automatisation complexe et le développement logiciel. Et sur ce terrain, les résultats sont éloquents.
J’ai testé pour vous (enfin, via les équipes de kilo.ai qui ont fait le sale boulot) : Kimi K2.6 a été laissé tourner en autonomie complète pendant 13 heures consécutives sur un projet réel. Résultat : plus de 1 000 tool calls exécutés, 4 000+ lignes de code modifiées, et un pipeline qui tient la route du début à la fin. Ce type de performance sur une tâche longue, c’est ce qui différencie un bon modèle d’un vrai moteur d’automatisation.
- SWE-Bench Pro : Kimi K2.6 obtient 58,6 % — devant GPT-5.4 (57,7 %) et Claude Opus (estimé comparable). DeepSeek V4 Pro n’a pas été mesuré directement sur cette version du benchmark.
- Function calling : Les deux modèles supportent nativement les tool calls / function calling — indispensable pour les workflows agentic.
- Structured output : Supporté par les deux — crucial pour les intégrations API propres.
- Avantage Kimi sur le visuel : Kimi K2.6 supporte les images en input — ce qui ouvre la voie à des agents capables de debugger une UI à partir d’un screenshot, d’analyser un tableau en image, ou d’interpréter un dashboard.
DeepSeek V4 Pro reste solide sur le coding pur, notamment sur la connaissance technique profonde et le raisonnement structuré. Mais sur les tâches agentic de longue haleine — celles qui durent des heures et enchaînent des dizaines d’actions — Kimi K2.6 est aujourd’hui mieux documenté et plus performant.
Conseil Romain : Pour une PME qui veut automatiser un processus (revue de code, génération de rapports, pipeline de traitement de données), Kimi K2.6 est le choix le plus solide en ce moment. La combinaison coding + agentic + images, c’est rare — et ça vaut vraiment le coup de tester.
Support image et multimodal : l’avantage silencieux de Kimi K2.6
On ne parle pas assez de ça. Et pourtant, c’est un différenciant majeur qui peut changer radicalement votre architecture d’agent IA.
Kimi K2.6 supporte les images en input. DeepSeek V4 Pro, non. C’est tout, c’est aussi simple que ça — mais les implications pratiques sont nombreuses.
| Fonctionnalité multimodale | DeepSeek V4 Pro | Kimi K2.6 |
|---|---|---|
| Texte en input | Oui | Oui |
| Images en input | Non | Oui |
| Audio en input | Non | Non |
| Vidéo en input | Non | Non |
| Output type | Texte uniquement | Texte uniquement |
Les cas d’usage concrets pour une PME ? Analyser un screenshot d’interface pour du debugging front-end. Extraire des données d’un tableau scanné en image. Interpréter un dashboard exporté en PNG.
Vérifier la cohérence visuelle d’un document. Rien de révolutionnaire individuellement — mais combiné avec les capacités agentic de Kimi K2.6, ça ouvre des possibilités d’automatisation que DeepSeek V4 Pro ne peut pas offrir, point.
Attention cependant : aucun des deux ne génère d’images en output. On reste sur du texte uniquement des deux côtés.
Verdict : DeepSeek V4 Pro ou Kimi K2.6 — lequel choisir ?
On se dit tout ? Voici la checklist décisionnelle que j’aurais aimé trouver quand j’ai commencé à tester ces deux modèles.
| Si vous avez besoin de… | Choisissez |
|---|---|
| Traiter des documents très longs (400+ pages) ou du RAG sur corpus massif | DeepSeek V4 Pro (1M tokens) |
| Générer beaucoup de texte ou de code (output-heavy) | DeepSeek V4 Pro (output moins cher) |
| Licence ouverte sans conditions (MIT) | DeepSeek V4 Pro |
| Raisonnement et connaissance technique profonde | DeepSeek V4 Pro |
| Coding et automatisation de tâches complexes (agentic) | Kimi K2.6 |
| Analyser des images (screenshots, scans, dashboards) | Kimi K2.6 |
| Vitesse d’inférence et réactivité temps réel | Kimi K2.6 |
| Analyse documentaire intensive (input-heavy) | Kimi K2.6 (input moins cher) |
| Agent IA long-horizon (tâches de plusieurs heures) | Kimi K2.6 |
Sur les benchmarks d’intelligence open source, Kimi K2.6 prend la première place en mai 2026. Sur le context window et la licence MIT, DeepSeek V4 Pro est imbattable. Les deux modèles sont excellents — la vraie question n’est pas « lequel est le meilleur », c’est « lequel colle à votre workflow ».
À retenir : Kimi K2.6 = le choix n°1 pour l’agentic, le coding et les workflows multimodaux. DeepSeek V4 Pro = le choix n°1 pour le long context, la génération intensive et la liberté de licence. Dans le doute ? Testez les deux via OpenRouter avec un budget de quelques euros — vous aurez votre réponse en moins d’une heure.
Questions Fréquentes
Kimi K2.6 est-il vraiment open source ?
Oui, les poids sont disponibles sur HuggingFace — mais attention à la licence. Kimi K2.6 est distribué sous une licence « Other », qui n’est pas aussi permissive que le MIT de DeepSeek V4 Pro. En clair : avant de l’intégrer dans un produit commercial à grande échelle, vérifiez les conditions d’utilisation directement auprès de MoonshotAI. Pour un usage interne ou expérimental, vous êtes tranquille.
DeepSeek V4 Pro supporte-t-il les images ?
Non. DeepSeek V4 Pro est un modèle texte uniquement en input. Si votre workflow implique l’analyse d’images, de screenshots ou de documents scannés, Kimi K2.6 est le seul des deux à pouvoir le faire. C’est un différenciant majeur souvent ignoré dans les comparatifs.
Quel modèle est le moins cher à l’usage réel ?
Ça dépend de votre ratio input/output. Kimi K2.6 est moins cher en input (0,95 $ vs 1,74 $ par million de tokens), mais plus cher en output (4,00 $ vs 3,48 $). Pour un usage output-heavy comme la génération de code ou de contenu, DeepSeek V4 Pro est globalement plus économique. Pour de l’analyse documentaire intensive, Kimi K2.6 gagne. Le seul moyen de savoir vraiment ? Tester avec vos propres données.
Kimi K2.6 ou DeepSeek V4 Pro pour de l’agentic AI ?
Kimi K2.6 est la recommandation claire pour l’agentic. Il est numéro 1 open weights sur l’Artificial Analysis Intelligence Index, affiche 58,6 % sur SWE-Bench Pro (devant GPT-5.4), et a été testé en conditions réelles sur une tâche autonome de 13 heures avec plus de 1 000 tool calls exécutés sans décrochage. DeepSeek V4 Pro est fort sur le raisonnement, mais les données comparatives sur l’agentic long-horizon lui manquent encore.
Comment accéder à ces modèles en API ?
Deux options principales : OpenRouter (le plus simple pour tester) ou les APIs officielles. Pour DeepSeek V4 Pro, rendez-vous sur api.deepseek.com. Pour Kimi K2.6, l’accès API passe par platform.moonshot.cn. OpenRouter agrège les deux avec un pricing transparent et une interface unifiée — idéal pour comparer les deux sur vos propres cas d’usage sans engagement.
Quelle est la différence de context window entre les deux ?
DeepSeek V4 Pro : 1 million de tokens. Kimi K2.6 : 256 000 tokens. Concrètement, 1 million de tokens équivaut à environ 1 500 pages A4 — ce qui est colossal. Pour les 95 % d’usages courants en entreprise, 256 000 tokens de Kimi K2.6 sont plus que suffisants. La différence devient critique uniquement pour les systèmes RAG sur très grandes bases documentaires ou les analyses de code sur des repositories massifs.
DeepSeek ou Kimi : la vraie leçon de 2026
En 2026, le débat DeepSeek V4 Pro vs Kimi K2.6 illustre parfaitement la maturité atteinte par l’open source IA. Les deux modèles rivalisent avec les meilleurs propriétaires — et dans certains domaines, les dépassent. C’est une rupture qui change concrètement ce qui est accessible aux PME, aux indépendants et aux équipes tech sans budget illimité.
Kimi K2.6 prend la tête sur l’intelligence open weights, le coding, l’agentic et le multimodal. DeepSeek V4 Pro s’impose sur le long context, la génération intensive et la liberté de licence. J’ai testé pour vous (et je ne regrette rien) : les deux méritent une place dans votre boîte à outils, selon les cas d’usage.
Le vrai enjeu de cette comparaison deepseek v4 vs kimi k2.6, ce n’est pas de trouver le « meilleur modèle IA open source » en absolu — c’est de trouver celui qui colle à votre workflow. Testez les deux via OpenRouter avec quelques euros de crédit. Vous aurez votre réponse en moins d’une heure.

Je publie et développe des médias web sur divers sujets depuis plus d’une décennie, et La grange du Web représente notre projet le plus récent. Nous souhaitons apporter toujours plus de valeurs et de qualité à nos articles afin de vous faire découvrir notre passion pour les nouvelles applications du web. Notre but est de vous aider à développer votre business avec les meilleurs services du b2b. Nous souhaitons vous apporter toujours plus d’informations sur les nouvelles tendances du web et les outils disponibles pour vous faire avancer avec votre entreprise



